
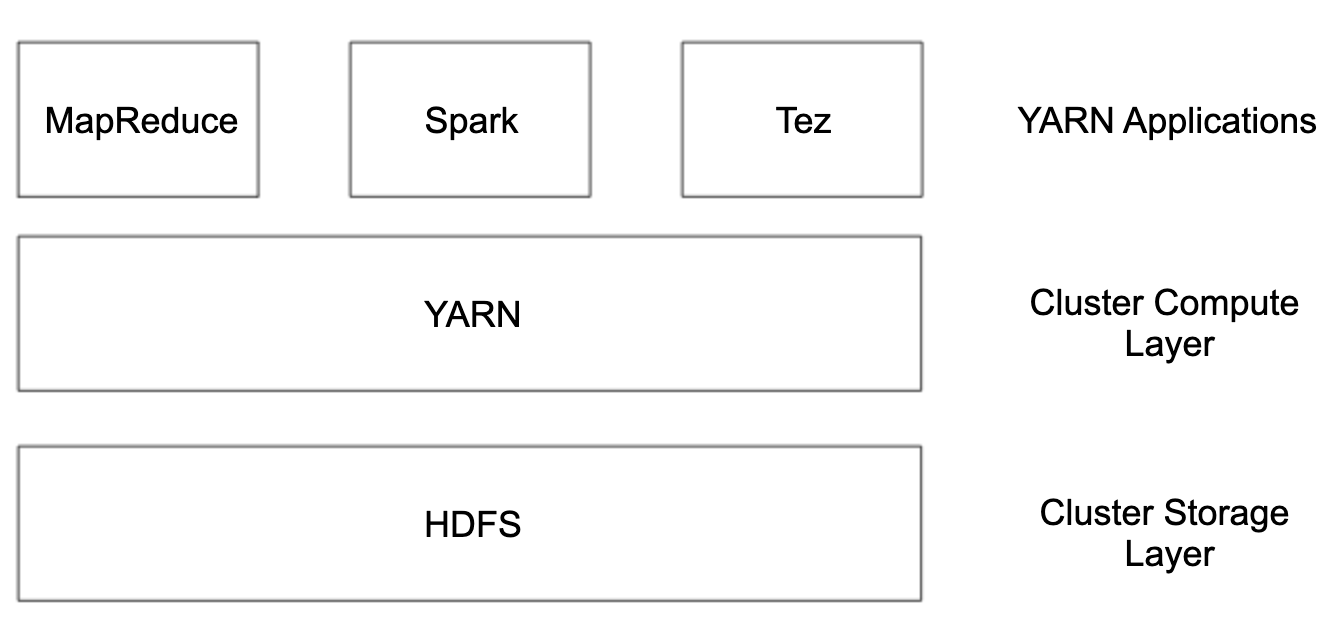
YARN
YARN은 클러스터에 컴퓨팅 리소스들을 관리하고, HDFS는 클러스터의 리소스 저장공간을 관리
아키텍처
동작방식
- 어플리케이션이 클러스터에 작업을 분배하기 위해서 Resouce Manager와 통신
데이터 로컬리티를 명시함 - 어느 HDFS블럭(들)을 처리하고자 하는가?
- YARN은 HDFS블럭들을 갖고있는 노드에서 처리하려고 노력함
- 어플리케이션에 대해서 다른 스케줄링 옵션 명시가능
- 클러스터에 즉시 하나이상의 어플리케이션 실행가능
- Scheduling Type
- FIFO :선입선출 방식으로 잡을 실행
- Capacity : 충분한 공간을 가진 노드가 있으면 잡을 병렬적으로 실행
- Fair : huge 잡으로 부터 조금의 리소스를 가져와서 가벼운 잡에 할당
MESOS
- Twitter에서 개발 - 데이터 센터들에 있는 자원들을 관리하는 시스템
- 빅데이터 뿐아니라 웹서버, 실행 스크립트 등에도 자원을 할당가능
- YARN은 하둡테스크들에 제한되지만, MESOS는 보다 더 일반적인 문제를 해결 - general container management system
- 하둡 에코시스템의 일부는 아니지만 잘 호환됨.
- Spark, Storm은 둘다 Mesos에서 동작가능
- Hadoop YARN과 Myriad를 사용해서 통합가능
YARN vs Mesos
- YARN은 monolithic scheduler - 잡을 할당하면, YARN이 알아서 어디서 실행할지 파악
Mesos는 Two-tiered system
Mesos는 어플리케이션에 대한 리소스 offer를 생성
어플리케이션 작성자가 offer를 수락할지 안할지 결정
사용자 정의 스케줄링 알고리즘을 정의가능
- YARN은 길고,analytical 잡들에 최적화되어있음.
- Mesos는 long-lived process, short-lived process 또한 다룰수 있음.
Tez
- Hive,Pig, 또는 MapReduce 잡들을 더 빠르게 함.
- 분산잡들을 더 효율적으로 처리하기위해 Directed Acyclic Graphs(DAGs) 생성
- 물리적인 데이터 흐름, 리소스 사용을 최적화
MapReduce vs Tez 성능비교
10만개의 영화 레이팅 정보를 대상으로 다음 쿼리를 작성했을때
1
2
3
4
5
6
7
8
9
10
DROP VIEW IF EXISTS topMovieIDs;
CREATE VIEW topMovieIDs AS
SELECT movie_ID, count(movie_id) as ratingCount
FROM movielens.ratings
GROUP BY movie_id
ORDER BY ratingCount DESC;
SELECT n.name, ratingCount
FROM topMovieIDS t JOIN movielens.names n ON t.movie_id = n.movie_id;
MapReduce로는 1분 11초가량, Tez 로는 21초가량이 걸린다.