From Apache Kafka to Amazon S3: Exactly Once
eventually consistent S3에서 exactly once streaming을 구현한 방법
- S3 multipart uploads: This feature enables us to stream changes gradually in parts and in the end make the complete object available in S3 with one atomic operation
- Utilize fact that Kafka and Kafka partitions are immutable : 같은 범위의 offset에 해당하는 파일을 두번 업로드하면, 결국 같은 파일을 업로드하게 됨.
multipart upload를 사용하면 S3 Connector는 각각의 파일을 part로 나누어서 점진적으로 업로드한다, 하지만 이 과정은 유저에게는 보이지 않는다. 유저는 오직 마지막 결과 파일만 볼 뿐이다. 결국 여러번의 실패가 발생하더라도, 파일을 읽는 앱입장에서는 완성된 S3 object들만 읽게 된다.(생성중인 S3 object들은 읽을수 없다.)
실패발생시 또는 restart할 경우, 커넥터는 그만둔 부분부터 데이터를 다시 처리할수 있다. 이 말은 완료되지 않은 part들중 일부를 다시 업로드할수 있음을 의미한다.
Kafka만이 유일한 source of truth이다. 이 사실은 장애복구과정을 매우 단순화시킨다. connector는 단지 파일 업로드가 성공하면 offset을 commit하면 된다. 커넥터 재시작시, 커넥터 워커는 남은 부분부터 즉시 레코드들을 처리하기 시작한다.
데이터를 로컬 디스크에 저장하지 않으므로, 커넥터는 속도가 향상된다. 카프카가 resilience를 책임지고(카프카에 장애가 생기면 문제가 생길수 있다.), 커넥터는 stateless fashion으로 데이터를 추출하기 위해서 scale up될수 있다.
3가지 시나리오
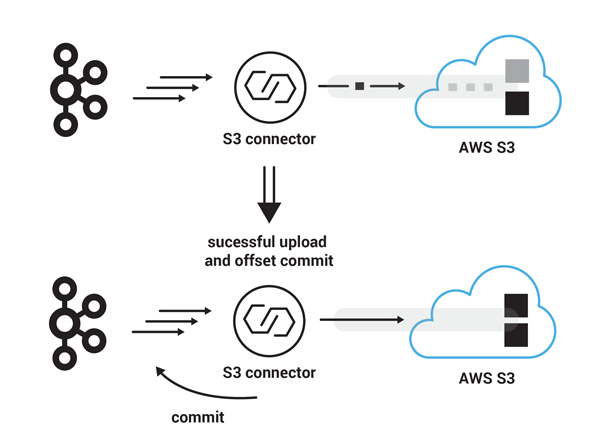
- S3 connector가 90 record마다 새로운 파일을 생성하는 파티셔너를 사용한다고 하자. 각각의 레코드는 1MB이고 connector는 25MB 각각의 여러 parts를 업로드하도록 설정되어있다. 이때 커넥터가 180번 offset부터 레코드들을 컨슘하다고 가정하자. 커넥터는 25MB 크기의 part 세개를 성공적으로 업로드 한뒤, 남은 15MB에 대해서 업로드를 진행하고 커넥터는 multipart upload를 완료한다. S3는 parts를 하나의 파일로 합친다. 이 작업은 S3에서 매우 빠르게 처리된다. 마지막으로 S3 커넥터는 multi part 업로드가 완료된 시점에, 성공적으로 업로드된 마지막 카프카 레코드의 offset를 커밋한다. 따라서 다음 starting kafka record offset은 270번이 된다.
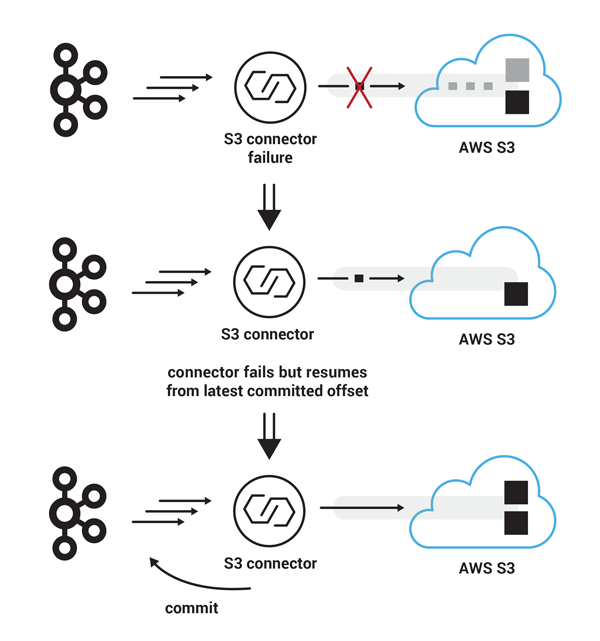
- 비슷한 시나리오로, S3 커넥터가 추가로 90개의 레코드를 S3로 업로드하기 시작한다고 하자. 그러나 이 경우에 part four를 업로드하는 과정에 Connect cluster에 심한 장애가 생겨서 S3 커넥터가 offline되었다고 해보자. 이러한 실패가 S3 커넥터가 90개의 레코드들을 하나의 파일로 업로드하는것을 방해했을지라도, S3 유저 입장에서는 partial data형태의 실패현상을 보지 못한다, 왜냐하면 파일이 아직 보이지 않기 때문이다. 일단 S3 커넥터가 다시 복구가 되고 나면, latest committed Kafka record offset부터 처리하기 시작할 것이고(이 경우에 여전히 270번 오프셋부터 처리하기 시작) 이번에는 four parts 모두 업로드가 성공적으로 끝난다면, S3에 90레코드에 대한 파일이 제대로 위치될것이다. 다음에 컨슘할 카프카 오프셋은 이제 360이 된다.
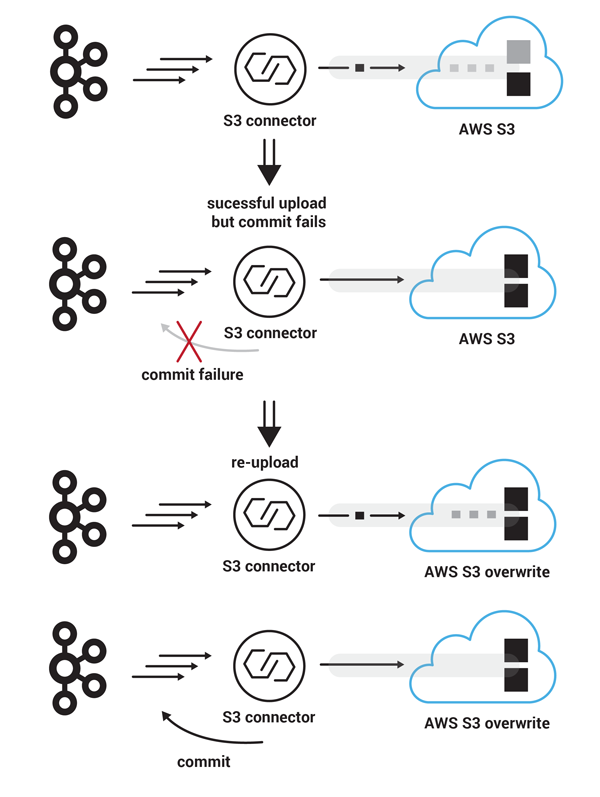
- 이번에는 다른 실패상황을 생각해보자. 먼저 추가로 90개의 레코드들을 S3로 업로드한다고 가정하자. multipart upload는 S3측에서 성공했지만, Kafka로 offset commit message가 유실이 되었다고 가정하자. 이 경우에는 S3 커넥터는 latest saved Kafka offset부터 다시 처리하기 시작한다(즉 360번 offset). 그리고 S3에 업로드가 완료되었다고 하자, 이 상황에서도 S3 커넥터는 중복을 피할수 있는데, 그 이유는 이전 파일이 동일 이름을 가진 파일로 overwrite되기 때문이다. 이 경우에도 offset commit이 성공한다면, S3 커넥터는 450번 offset부터 컨슘하게 된다.