
Resilient Distributed Dataset(RDD)
RDD는 데이터의 immutable distributed collection, 클러스터의 노드들에 분할되어있고 병렬적으로 처리됨. 여러 분산 노드에 걸쳐서 저장되는 변경이 불가능한 데이터(객체)의 집합으로 각각의 RDD는 여러개의 파티션으로 분리가 됩니다. 즉, 스파크 내에 저장된 데이터를 RDD라고 하고, 변경이 불가능하며, 변경을 하려면 새로운 데이터 셋을 생성해야 합니다.
언제 RDD를 사용하는가?
- dataset에 대해서, low-level transformation, action, control이 필요할때
- media stream, text stream과 같이 데이터가 unstructured 구조일때
- functional programming으로 데이터를 다루고 싶을때
- columnar format과 같은 스키마를 써도 상관없는 경우
DataFrame
- rdb 테이블처럼, 데이터가 named column으로 정리되어있음
- RDD처럼 immutable distributed collection of data
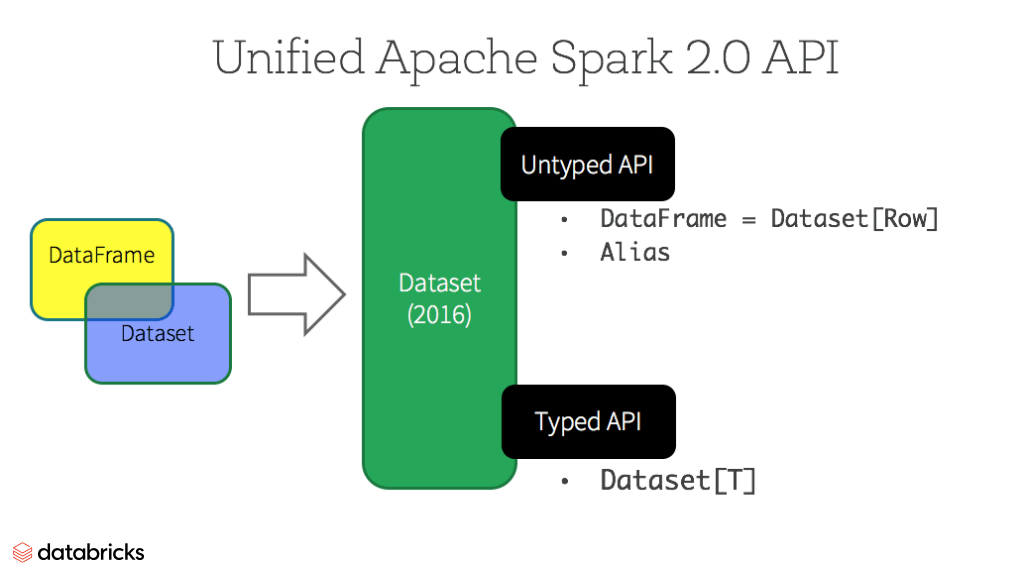
Dataset
Spark 2.0부터 Dataset은 두가지 다른 성질의 API를 제공한다: strongly-typed API, untyped API
개념적으로 DataFrame은 generic Dataset[Row] 객체 컬렉션의 별칭으로 볼수 있다. ROW는 untyped JVM 객체이다. Dataset은 대조적으로, strongly-typed JVM 객체 컬렉션으로 볼수 있다.
Typed and Un-typed APIs
| Language | Main Abstraction |
|---|---|
| Scala | Dataset[T] & DataFrame(alias for Dataset[Row]) |
| Java | Dataset[T] |
| Python | DataFrame |
| R | DataFrame |
Dataset API의 장점
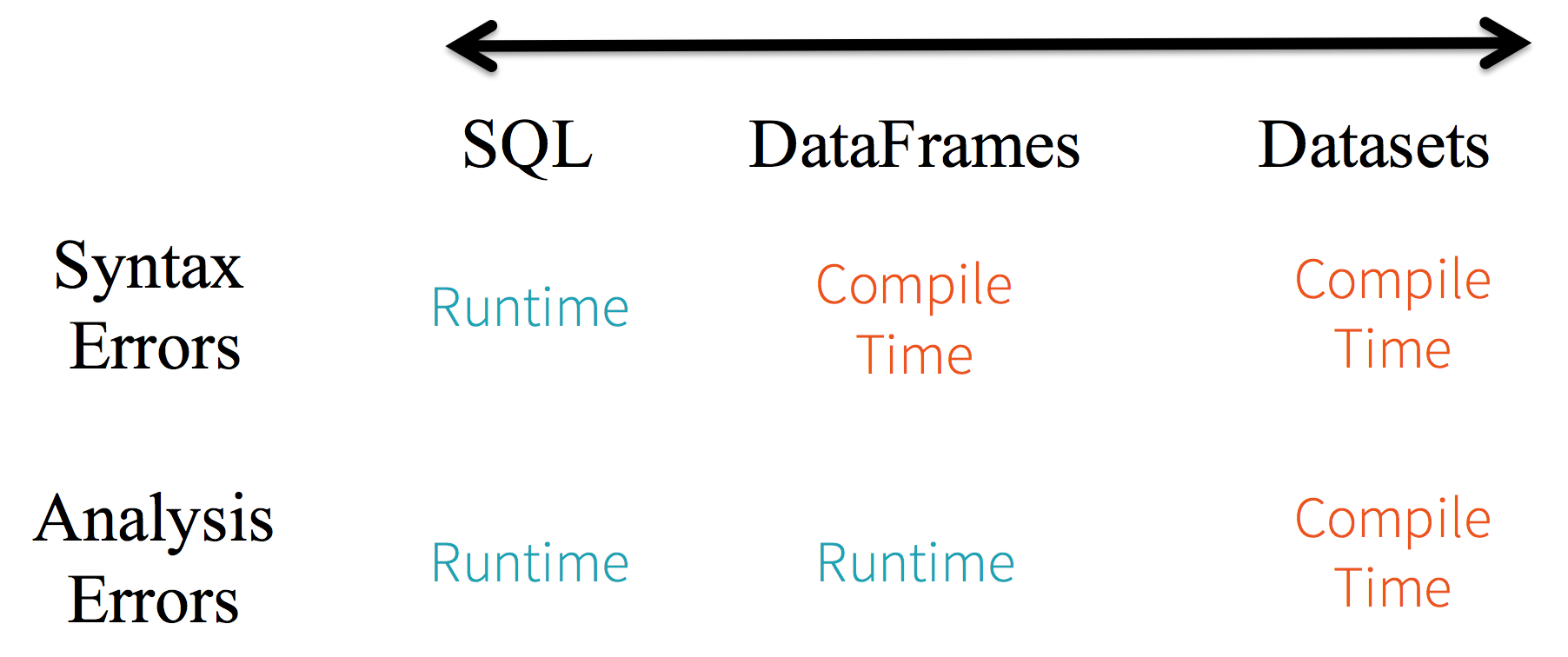
1. Static-typing, runtime type-safety
SparkSQL의 경우 runtime 전까지 문법오류를 알수 없다. 반면에 DataFrame이나 Dataset를 사용할경우 compile 시간안에 에러를 알수 있다.(시간이 절약된다.) 즉 DataFrame api의 일부가 아닌 함수를 호출하면, 컴파일러가 오류를 감지한다. 하지만 존재하지 않는 컬럼네임을 감지하는것은 런타임 전까지는 알수 없다.
2. Structured and semi-structured data에게 High-level abstraction과 custom view 제공
DataFrame은 semi-structured data에게 structed custom view를 제공할수 있다. 예를들어, 대용량 IoT device event dataset이 있다고 가정하고, 포맷이 JSON으로 되어있다고 하자. JSON은 semi-structued format이기 때문에 Dataset[DeviceIoTData] 라는 강한 정적타입으로 변환 될수 있다.
1
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip": "80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius", "temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408, "lcd": "red", "timestamp" :1458081226051}
1
2
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)
그리고 JSON 파일을 다음처럼 읽을수 있다.
1
2
3
4
// read the json file and create the dataset from the
// case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
val ds = spark.read.json(“/databricks-public-datasets/data/iot/iot_devices.json”).as[DeviceIoTData]
내부적으로 다음과 같은 일이 일어난다.
- Spark가 JSON을 읽고, schema를 추론한다 그리고 DataFrame 컬렉션을 생성한다.
- 이 시점에, Spark은 정확한 타입을 모르기 때문에 데이터를 DataFrame=Dataset[Row]으로 변환한다.
- 그리고 Spark은 Dataset[Row] -> Dataset[DeviceIoTData] (type-specific Scala JVM object)로 변환한다.
결과적으로 다음과 같이 시각화 할수 있다.
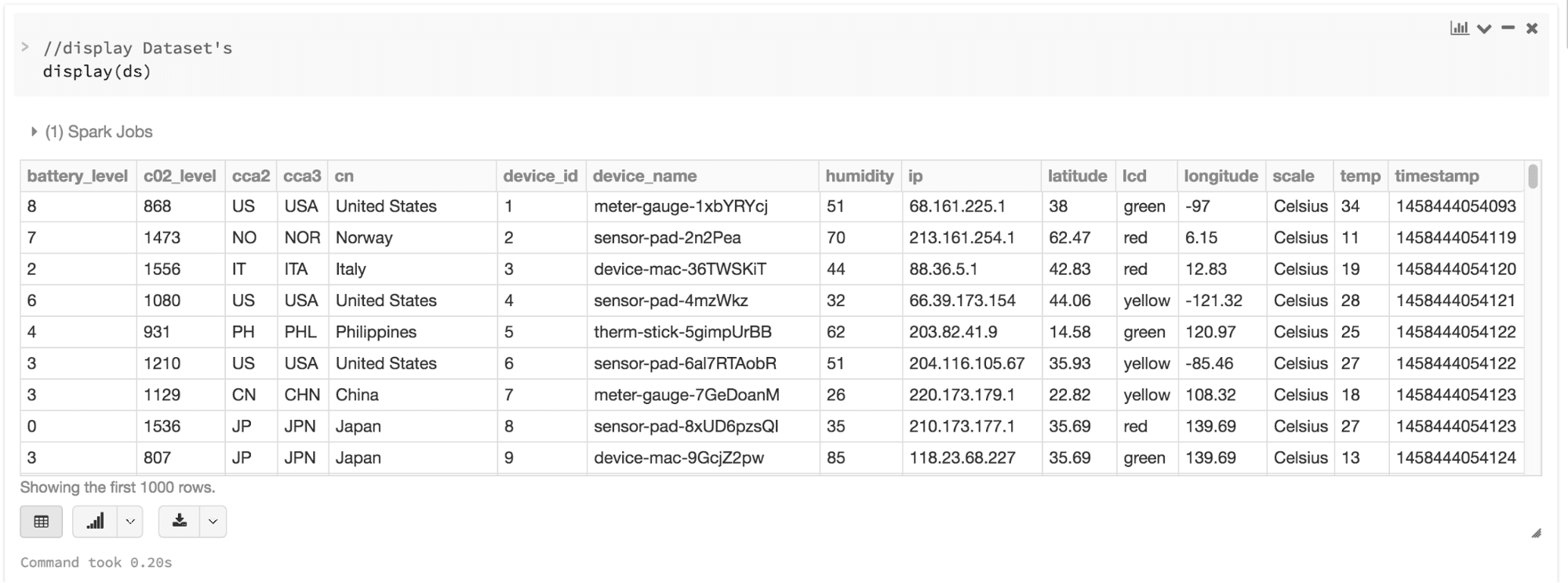
3. Ease-of-use of APIs
Dataset의 high level api를 이용하면, agg, select, sum 등 다양한 연산을 할수 있고 RDD row의 데이터 필드를 사용하는것보다 훨씬 간단하다.
4. Performance and Optimization
DataFrame과 Dataset API는 RDD에 비해서 공간 효율적이고 퍼포먼스가 좋은데 이유는 두가지이다.
DataFrame과 Dataset API는 Spark SQL engine을 기반으로 만들어졌기 때문에, 논리적.물리적 쿼리 플랜을 생성하기 위해서 Catalyst를 사용한다. R.Java.Scala.Python 모두 쿼리들은 같은 코드 optimizer를 실행하고, 시간.공간 효율적인 코드로 최적화된다. Dataset[T] 타입 API는 데이터 엔지니어링 테스크에 최적화되어있고, untyped Dataset[Row] 즉, DataFrame은 interactive analysis에 최적화되어있다.

두번째 이유는 Spark as a compiler 가 Dataset type JVM 객체를 이해하기 때문에, Encoders 를 사용해서 type specific JVM object를 Tungsten’s internal memory representation으로 맵핑한다. 결과적으로 TungstenEncoder는 효율적으로 JVM 객체를 직열화/역직열화 할수 있을 뿐만아니라 빠른속도로 실행될수 있는 compact byte code를 생성한다.
DataFrame, DataSet을 써야하는 경우
- Rich semantics, high-level abstraction, domain specific API를 원할경우
- filters,maps,aggregation,averge,sum,sql query, columnar access, semi-structured data에 대해서 lambda function을 사용할경우
- 컴파일시간에 type-safety, typed JVM object, Catalyst optimization, Tungsten’s efficient code generation을 이용하고 싶은 경우