
PySpark Overview

PySpark은 Spark의 Java API를 기반으로 구현되었다. 데이터는 Python에서 처리되고 JVM에서 cache/shuffle 된다.
RDD API 실행 과정
- Python driver program에서, SparkContext는 Py4J 라이브러리를 사용하여 JavaSparkContext를 사용하는 JVM을 실행한다.
- Py4J는 오직 Python과 Java SparkContext간의 로컬 커뮤니케이션 용도에만 사용된다. Python RDD transformation은 Java에 있는 PythonRDD 객체들에 대한 transformation으로 맵핑된다.
- Python RDD 객체들이 워커노드로 푸시된다. 워커노드에서는 PythonRDD 객체들은 Python subprocess를 실행하고 pipe를 사용하여 통신한다. 결과적으로 사용자의 코드와 데이터가 Python에서 처리된다.
Python RDD communications
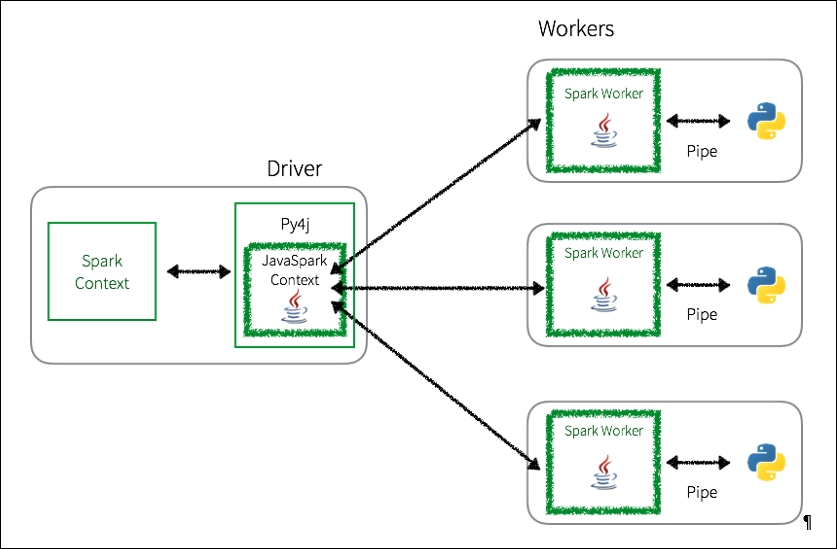
이 방법이 PySpark이 여러 워커에 있는 Python subprocesses에게 데이터 처리를 분산시키지만, JVM과 Python Process간에 context switching이 많이 일어난다.
출처
Spark 기반에서 Python과 Scala API의 성능 비교 분석 https://subscription.packtpub.com/book/big_data_and_business_intelligence/9781786463708/3/ch03lvl1sec17/python-to-rdd-communications