
기존의 문제점
오라클 데이터베이스가 Single Point Of Failure
오라클 데이터베이스의 scale up 비용증가
오라클 데이터베이스의 부하증가
PostgreSQL가 Oracle에 비해 좋은점
Distributed Database
CDC 파이프라인 구성 용이
CITUS
CITUS는 postgres에 대한 extention
CITUS회사 왈
- RDBMS는 general-purpose data platform
- “RDBMS는 스케일아웃이 불가능한것이 아니라 힘든것뿐이다.”
- 힘든 이유 3가지
- Distributed table
- Optimize distributed sql
- Distributed transaction
CDC(Change Data Capture) 파이프라인
CDC
- 데이터베이스의 변경분을 추출하기 위한 프로세스 및 솔루션
- 활용: replication, event driven, architecture
- Ex) GoldenGate(Oracle), Binlog(MySQL), WAL(PostgreSQL)
Advantages
- 이종 DBMS간 복제를 통한 부하 분산
- Stream 기반 실시간 데이터 파이프라인 처리
- 데이터 변경 이력 관리
Debezium
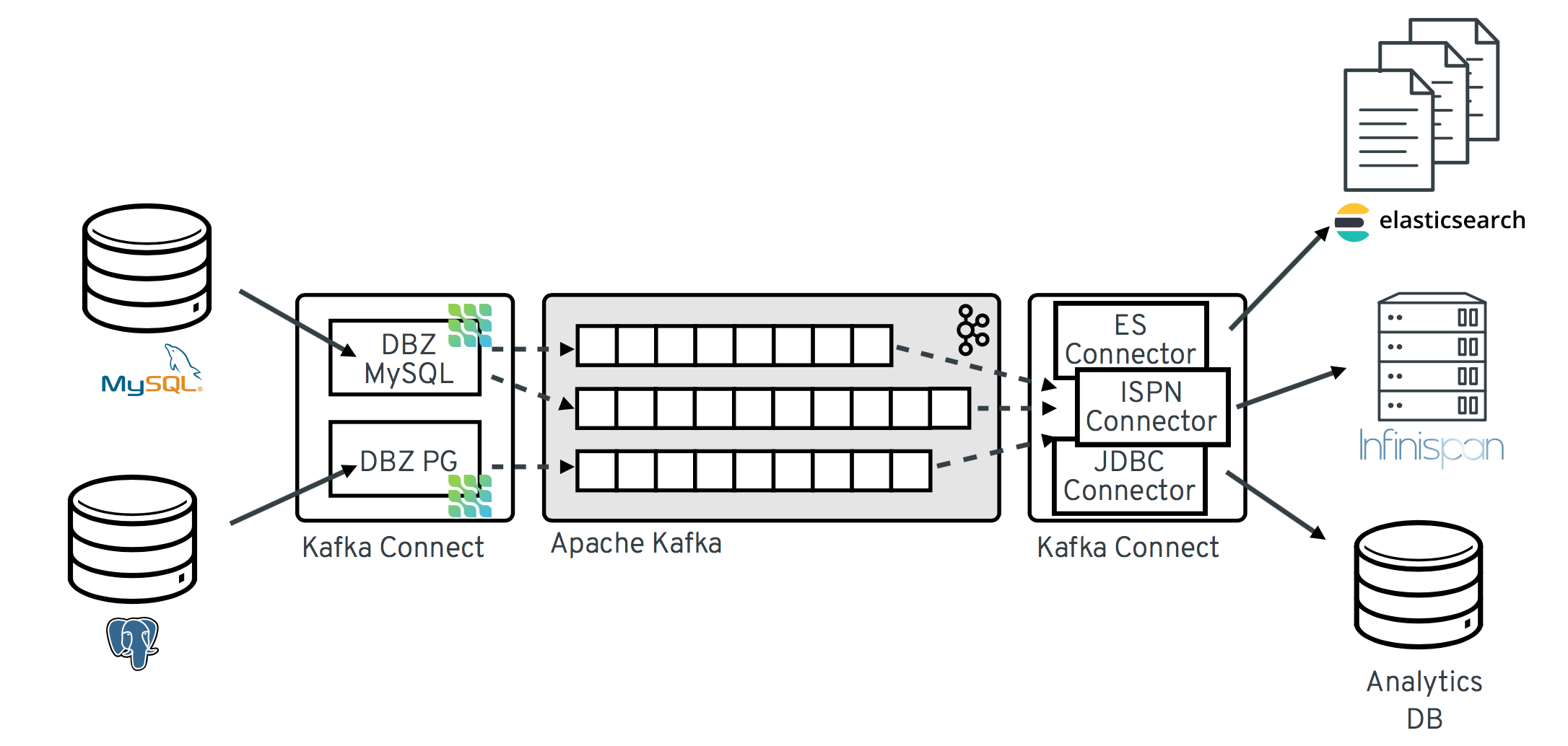
- 다양한 데이터베이스의 CDC를 추출하기 위한 오픈 소스 플랫폼
- Kafka Source Connector 기반
지원하는 데이터베이스
- MySQL, PostgreSQL, MongoDB 등
- Schema Registry를 통해 스키마 관리
- compatibility : FORWARD
Debezium CDC format
Key schema
- 테이블의 primary key, pk가 없을 경우 unique key에 대한 스키마
- key payload
- 변경 row의 key 데이터로 key schema를 따름
- 테이블의 pk
value schema
- 테이블의 컬럼에 대한 event value 스키마
- value payload
- 변경 row의 모든 칼럼에 대한 데이터로 value schema를 따름
테이블의 모든 칼럼
- before : 변경 이전 값
- after : 변경된 값
- op : operation type
- c: CREATE
- u: UPDATE
- d: DELETE
- transaction (provide.transaction.metadata 셋팅 필요)
- id : string representation of unique transaction identifier
- total_order : absolute position of the event among all events generated by the transaction
- data_collection_order : the per-data collection position of the event among all events that were emitted by the transaction
Tombstone
- delete시 value를 null로 하여 key event를 한번 더 보내는 옵션
- Kafka log compaction 시 이전 데이터 삭제할수 있어 효율적
- tombstones.
분산 DB로 존재하는 테이블정보를 하나의 토픽으로 수렴하는 과정
Debezium for CITUS
- debezium은 테이블 단위로 topic을 생성
- citus는 multiple shard기반의 분산 DB로 테이블 여러개 존재
- 따라서 테이블 당 shard개수 만큼의 topic이 생성되는 문제 발생
- Topic이 많아지고 consumer 관리가 힘들어짐
- table 200개 * shard 32개 = 6400개 topic
- postfix를 제거하고 하나의 topic으로 수렴시킬수 있다면? => Kafka Connect SMTs 로 해결
- cdc.public.product_102008
- cdc.public.product_102010
- cdc.public.product_102011
- cdc.public.product_102014
- …
Kafka Connect SMTs
Single Message Transformations(SMTs)
kafka connect flow중간에서 메시지를 변환할 수 있는 모듈
Cast,Drop등 기본 제공 모듈도 있고, java 인터페이스 기반으로 직접 제작도 가능
Schema Regsitry Versioning Issue
- schema registry 버전이 shard개수 만큼 계속 올라가는 문제
- 스키마의 namespace, connect.name등의 필드가 shard이름이 들어있기 때문
- 버전이 메시지 발행수 만큼 무한 증가하지는 않음
- Schema Registry가 MD5 Hash로 동일 스키마인지 구분하여 예전의 ID를 반환하기 때문
- 그렇다고 해도, 스키마 변경 횟수 * shard 갯수 만큼 버전 상승, 관리 어려움
JDBC Sink Connector
JDBC Sink Connector
- kafka의 cdc데이터를 DB에 반영하기 위한 connector
- JDBC driver를 이용하여 DB access
Data mapping
- Debezium의 CDC schema를 Connect Struct로 변환필요
- debezium-core의 transforms로 제공
- Io.debezium.transforms.ExtractNewRecordState
Idempotent write
- 멱등성 유지를 위한 upsert 지원
- insert.mode: upsert
Debezium Monitoring
JMX Exporter for Prometheus
Prometheus
- 오픈소스 모니터링/Alert 시스템
- Time-series 기반 다차원 데이터 모델
JMX Exporter
- JMX 으로부터 mBean을 특정 port로 expose하는 java agent
- prometheus에서 해당 endpoint 로부터 주기적으로 scrape
- kafka-connect 수행시 JAVA_OPTS에 다음과 같이 추가하여 사용
- Javaagent:/usr/share/libs/jmx_prometheus_javaagent-0.14.0.jar=8080:config.yaml
Debezium Metric
- MilliSecondsBehindSource
- 마지막 변경 event의 timestamp와 debezium이 읽은 timestamp의 차이
- 지연이 많아질수록 높은 값
- MilliSecondsSinceLastEvent
- 최근 debezium이 event를 처리한 시간과 현재 시간의 차이
- DB변경이 발생하지 않으면 값이 높아짐
MirrorMaker2
- Kafka cluster를 복제하기 위한 framework
- cdc용 kafka를 application용 kafka와 격리시기 위해 사용
- Source Connect 기반으로 별도로 offset을 기록하여 metric이 필요
Replication-latency-ms-avg
- Timespan between each record’s timestamp and downstream ack