
Hive와 Impala에 대한 소개
Hive와 Impala는 하둡시스템으로부터 데이터를 추출하기 위해서 SQL과 유사한 인터페이스를 제공하는 툴이다.
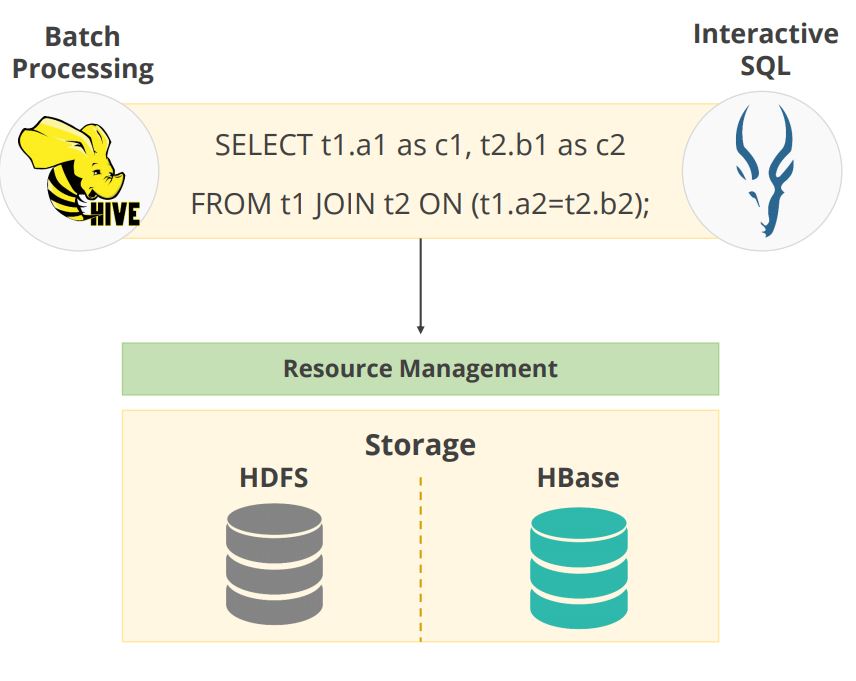
Impala vs Hive
| Impala | Hive |
|---|---|
| Google의 Dremel project에 의해 영감을 받아서 2012년 Cloudera에 의해서 개발 | Facebook에 의해서 2017년 개발 |
| Impala SQL을 사용하며 밀리세컨트 단위의 낮은 쿼리 latency 보장 | HiveQL을 사용하여 메타스토어에 있는 구조화된 데이터를 쿼리하며, MapReduce, Spark job들을 하둡 클러스터에 실행 |
| 효율적인 병렬처리로 인해 Hive보다 5~50배 가량 빠르며 interactive 쿼리와 데이터 분석에 적합 | 과거 데이터나 주기적인 리뷰탐색과 같은 구조화된 데이터에 적합하며 베치성 작업에 주로 사용 |
| 병렬적으로 여러 사용자들을 수용가능 | 한번에 여러 사용자 수용 불가 |
RDBMS vs Hive vs Impala
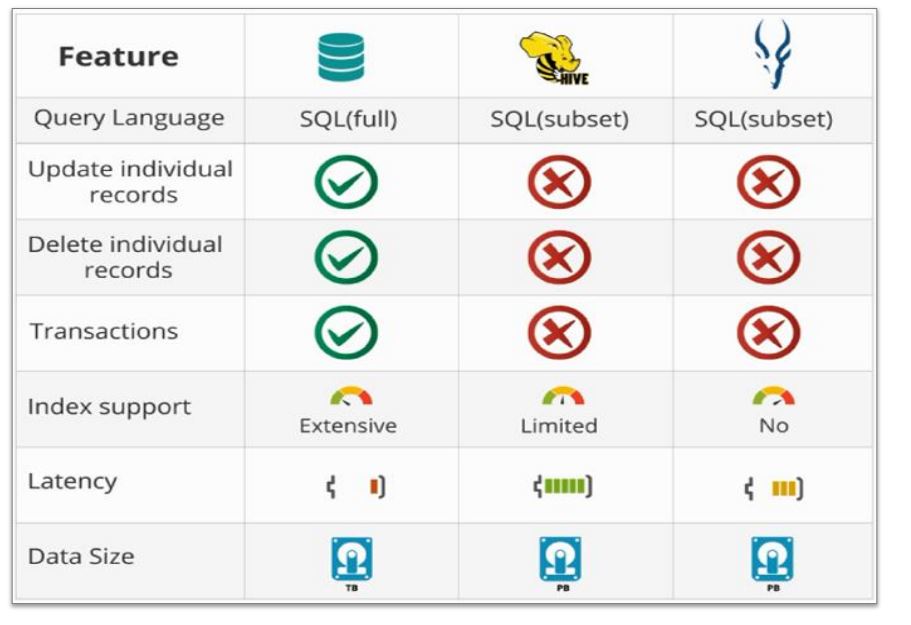
RDBMS는 레코드들을 업데이트, 삭제할수 있지만 Hive,Impala에서는 불가능하다.
트랜젝션 기능또한 RDBMS에서만 가능하다.
SQL 쿼리에 대한 지연시간 : RDBMS < Impala < Hive 순서이다.
RDBMS에서는 terabyte단위까지 저장 가능, Impala,Hive에서는 petabyte까지 가능
Hive와 Impala의 쿼리 실행방식 비교
먼저 Hive의 쿼리 실행방식은 다음과 같다.
HiveQL을 파싱
쿼리를 최적화
execution plan 생성
클러스터에 잡을 할당
진행상황을 모니터링
데이터 처리 : 잡이 맵리듀스로 변환되거나 스파크에 의해서 처리
결과 데이터를 HDFS에 저장
Impala는 다음과 같다.
Impala SQL 파싱
쿼리 최적화
execution plan 생성
클러스터에 쿼리 실행
데이터를 클러스터에 저장
임팔라는 맵리듀스나 스파크를 사용하여 데이터를 처리하지 않는 대신에, 클러스터에 쿼리를 직접 실행한다. 이러한 방식때문에 Impala가 Hive보다 빠르다.