
G1 Garbage Collector
server-style garbage collector이고 메모리가 많은 multi-processor 머신에서 사용된다. high throughput, low GC pause time을 목표로 한다. JDK 7 update 4 이후부터 지원하기 시작했다. 다음과 같은 앱을 위해서 디자인 되었다.
- CMS collector와 같은 어플리케이션 스레드와 병렬적으로 수행가능하다.
- 긴 GC pause time없이 free space를 compact 할수 있다.
- GC pause duration이 더 예상가능하다.
- throughput performance를 희생할 필요가 없다.
- Java Heap 공간이 많이 필요없다.
G1은 장기적으로 CMS 알고리즘을 대체하기로 계획되어있다. CMS와의 한가지 차이는, G1은 compacting collector라는 점이다. G1은 fine-grained free list를 할당을 위해서 사용할 필요없이, 메모리공간을 compact한다. 이는 collector의 동작을 간단하게 만들고 잠재적인 fragmentation 이슈들을 제거한다. 또한 CMS에 비해서 더 예상가능한 collection pause를 제공하고 사용자들이 원하는 pause target를 명시할수 있도록 해준다.
Overview
이전의 garbage collector(serial,parallel,CMS)는 모두 heap을 3가지 섹션으로 나눈다 : young generation, old generation, permanent generation.
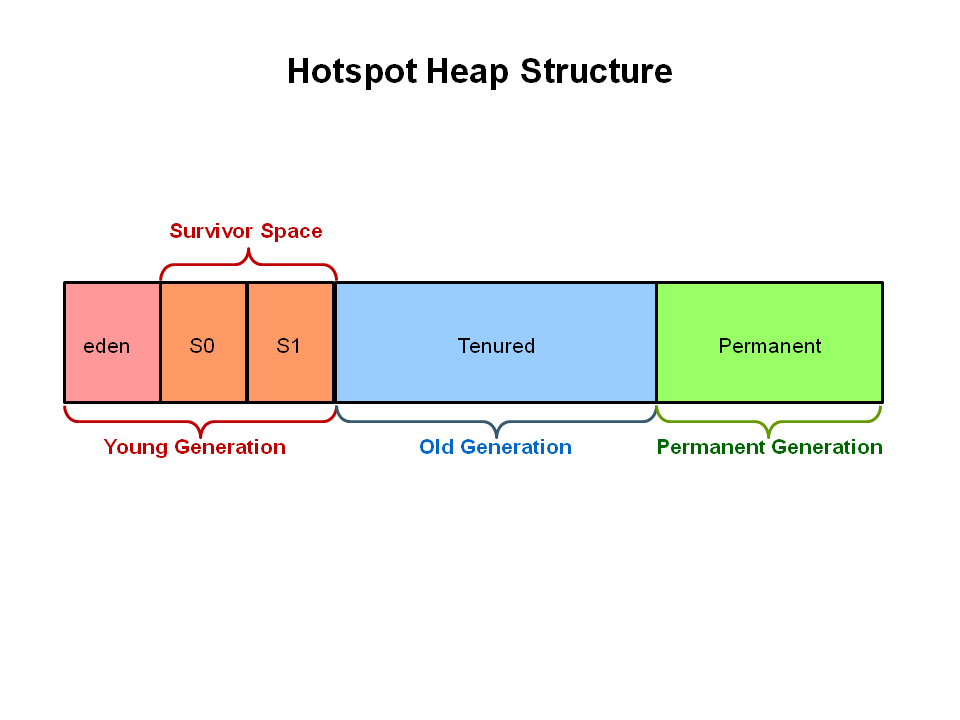
모든 메모리 객체들은 세가지 섹션에 속하게 된다.
G1 collector는 다른 접근을 갖는다.
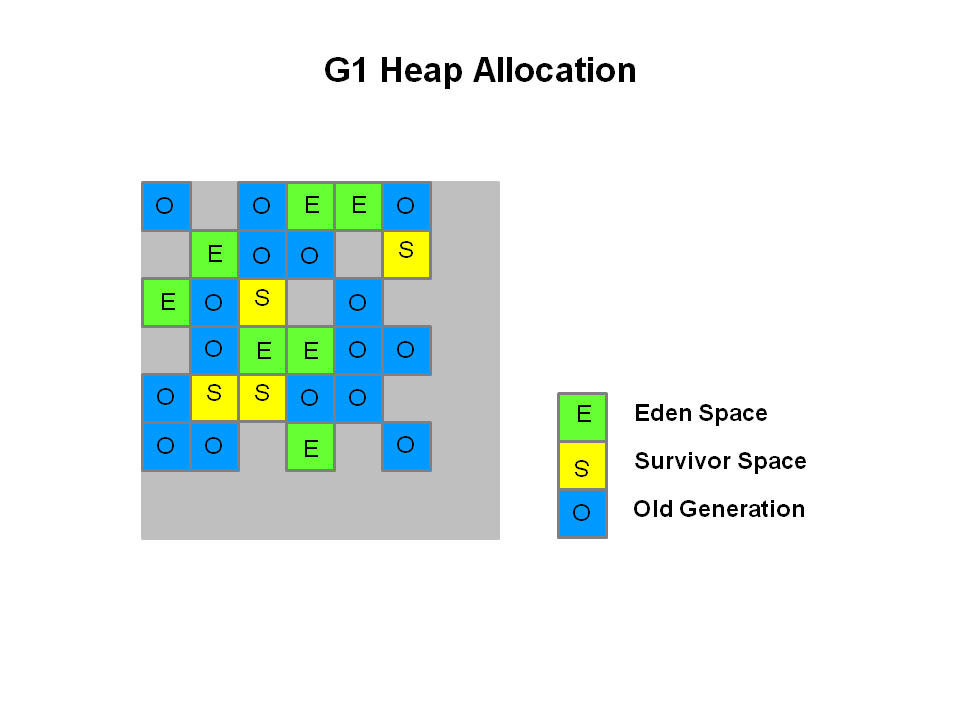
heap은 동일한 크기의 heap region으로 나누어지고, 각각은 virtual memory상에서 인접해있다. 특정 region은 이전의 garbage collector와 동일한 역할(eden,survivor,old)을 갖는다, 하지만 고정된 크기가 할당된것은 아니다. 이는 메모리 사용에 유연함을 제공한다.
garbage collection동작방식은 CMS와 비슷하다. G1은 heap 전체를 대상으로 객체들의 liveness를 결정하기 위해서 concurrent global marking phase를 수행한다. mark phase가 끝나면, 어느 region이 거의 비어있는지 알수 있다. 먼저 이러한 region의 메모리공간을 회수하여 free space를 많이 확보한다. 이러한 방식이 G1(garbage first)라고 불리는 이유이다. 이름에서 알수 있듯, G1은 reclaimable 객체들(줄여서, garbage)로 가득차있을것으로 예상되는 heap 영역에 대해서 collection,compaction을 집중한다. G1은 user-defined pause time을 만족하기 위해서 pause prediction model을 사용하고 명시된 specified pause time target에 기반하여 회수할 region의 갯수를 선택한다.
G1에 의해서 ripe 라고 식별된 region은 evacuation을 사용하여 수집된 garbage이다. G1은 heap의 한개이상의 region에 있는 객체들을 heap에 있는 단일 region으로 복사한다, 그 과정에서 memory를 compact, free up 한다. 이러한 evacuation은 멀티 프로세서에서 병렬로 수행되고, 결과적으로 pause time을 줄이고 throughput을 증가시킨다. garbage collection 매번, G1은 계속해서 fragmentation을 줄이고, user-defined pause time내에서 동작한다. 이는 이전의 방법들을 능가함을 뜻한다. CMS garbage collector는 compaction을 수행하지 않고, ParallelOld garbage collector는 오직 whole-heap compaction을 수행한다, 이는 상당한 pause time을 초래한다.
G1은 실시간 collector가 아니다. 높은 확률로 pause time target을 만족하지만 완벽하게 보장하지 않는다. 이전의 collection 데이터에 기반하여, G1은 user specified target time 내에 얼마나 많은 region이 수집될수 있는지 추정한다.
Note : G1은 concurrent(application thread와 함께 동작 eg. refinement, marking, cleanup) 단계와 parallel(multi threaded eg. stop the world) 단계를 모두 거친다. Full garbage collection은 여전히 single thread로 동작하지만 최적화하면 full GC를 피할수 있어야한다.
G1 Footprint
이전의 gc에서 G1으로 migration한다면 더 큰 JVM process size를 볼수 있을것이다. 이는 “accounting” 데이터 구조(Remembered Sets, Collection Sets)와 연관이 있다.
Remembered Sets(RSets)는 주어진 region에 대한 object reference를 추적한다. heap에는 region당 하나의 RSet이 존재한다. RSet은 병렬,독립된 수집을 활성화한다. RSet에 대한 overall footprint는 5%미만이다.
Collection Sets(CSets)는 GC에서 수집될 region들을 의미한다. CSet에 있는 live data는 GC 동안 evacuate(copied,moved)된다. region은 Eden,survivor,old generation이 될 수 있다. CSet은 JVM size에 대한 영향은 1% 미만이다.
추천하는 use case
G1의 첫번째 focus는 large heap에 낮은 GC latency가 필요한 어플리케이션을 실행하는 유저들에게 해결책을 제공하는 것이다. 이는 heap size가 6GB 이상인 경우를 말하고, stable and predictable pause time이 0.5초 미만인 경우를 말한다.
이전 gc를 사용할 경우 다음의 특성이 있다면 G1으로 교체하는 것이 좋다.
- Full GC duration이 너무 길고 빈번하다.
- object allocation rate나 promotion비율이 매우 다양하다.
- gc,compaction pause 시간이 너무 길다. (0.5~1초 보다 길다)