
Citus란?
여러 머신에 쿼리하고 데이터를 분산할수 있도록 하는 PostgreSQL의 extension. sharding과 replication을 사용해서 수평확장한다.
언제 사용하는가?
1. Multi-Tenant Database
- 모든 tenant에 빠른 쿼리가능
- database에 sharding logic이 있음
- 단일 노드 PostgreSQL보다 더 많은 데이터 소유가능
- SQL을 포기하는것 없이 Scale out
- high concurrency를 보장하고 동시에 퍼포먼스도 유지
- 빠른 metric 분석가능
- 신규 사용자를 다루기위해 쉽게 scale out 가능
2. Real-Time Analytics다.
- 데이터가 많아 지더라도 1초내에 응답가능
- 실시간으로 새로운 이벤트,데이터를 분석가능
- SQL 쿼리를 병렬적으로 실행가능
- dashboard query에 대해 빠른 응답가능
사용이 적절하지 않은경우
- 단일 노드 Postgres로 커버가 되는경우
- real-time ingest, real-time query가 필요없는 offline analytics의 경우
- 많은 사용자들에게 병렬적으로 기능을 제공할 필요가 없는경우
- 요약된 결과가 아닌, 무거운 ETL 결과를 리턴하는 쿼리의 경우
Concepts
1. Nodes
Coordinator and Workers
모든 클러스터는 coordinator 라는 특별한 노드가 있는데, 다른 노드들은 worker라고 부른다. 어플리케이션이 coordinator 노드에게 쿼리를 보내면, coordinator는 관련있는 worker에게 이를 전파하고 결과를 받아온다.
각각의 쿼리에 대해서, coordinator는 단일 worker로 요청으로 보내거나 요구되는 데이터가 여러 노드에 존재할경우에는 병렬적으로 여러 worker에게 요청을 보낸다. coordinator는 메타데이터 테이블와 소통하면서 이 과정을 어떻게 할지 알아낸다. Citus-specific table들은 DNS 이름들과 워커노드들의 health를 모니터링하고 노드들에 있는 데이터의 분포 또한 모니터링한다. 더 궁금하다면 다음 Citus Tables and Views를 참고하자.
2. Distributed Data
Table Types
Citus cluster에는 세가지 타입의 테이블들이 존재한다.
Type1 : Distributed Tables
첫번째 타입은 distributed table이다. SQL statement에 대한 보통 테이블처럼 보이지만 worker node에 수평적으로 partition되어있다.
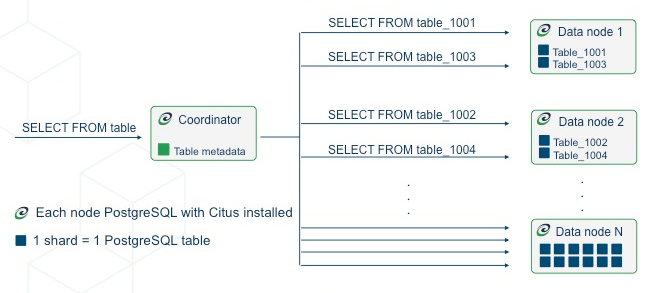
component worker table들을 shard라고 부른다. Citus는 SQL을 실행할뿐 아니라 DDL 문까지 실행한다. 따라서 분산 테이블의 스키마를 수정하면, 모든 워커들에 있는 모든 테이블의 샤드들에게 업데이트가 적용된다. 분산 테이블을 생성하는과정이 궁금하면 Creating and Modifying Distributed Tables (DDL)를 참고하자.
Distribution Column
Citus는 샤드들에게 행을 할당하기 위해서 algorithmic sharding을 사용한다. 이는 distribution column이라 불리는 테이블 칼럼에 기반을 두어 행을 할당하는것을 의미한다. 클러스터 관리자는 테이블을 분산할때 이 칼럼을 만드시 지정해야한다. 올바른 결정은 퍼포먼스나 기능수행을 위해서 중요하다. 더 궁금하면 Distributed Data Modeling를 참고하자.
Type 2 : Reference Tables
reference table은 컨텐츠가 하나의 샤드에 저장되고 모든 워커에 복제가 되어있는 테이블을 말한다. 각각의 워커에 대한 쿼리는 다른 노드에게 행을 요청할 네트워커 오버헤드 없이 로컬에 있는 정보를 접근할수 있다. Reference table은 행마다 독립적인 샤드들을 구분할 필요가 없기 때문에 distribution column이 없다.
더 궁금하면 Reference Tables 를 참고하자.
Type 3 : Local Tables
Citus를 사용할때 coordinator node는 일반 Citus extension이 설치된 PostgreSQL database이다. 따라서 테이블을 생성하고 shard하지 않도록 할수 있다. 이는 작은 관리 테이블의 경우에 유용하다. 예를 들면 application login, authentication을 위한 사용자 테이블이 있다. Citus는 cluster metadata를 저장하기 위해서 local table을 사용한다.
Shards
여기서는 shard를 세부적으로 알아보자.
1
2
3
4
5
6
7
8
SELECT * from pg_dist_shard;
logicalrelid | shardid | shardstorage | shardminvalue | shardmaxvalue
---------------+---------+--------------+---------------+---------------
github_events | 102026 | t | 268435456 | 402653183
github_events | 102027 | t | 402653184 | 536870911
github_events | 102028 | t | 536870912 | 671088639
github_events | 102029 | t | 671088640 | 805306367
(4 rows)
coordinator에 있는 pg_dist_shard 메타데이터 테이블은 시스템에 있는 각각의 분산 테이블 샤드의 행을 포함한다. row는 hash space내에 있는 정수들의 범위에 대응하는 shardid와 매치된다.
만약 coordinator 노드가 어느 샤드가 github_events의 행을 가지고 있는지 결정하려고 하면, row에 있는 distribution column 값을 해쉬하고 어느 샤드의 범위가 hashed value를 포함하는지 검사하면된다.
Shard Placement
샤드 102027에 대해서 질의 한다고 가정해보자. 이는 행이 github_events_102027 테이블에 대해서 읽혀지거나 쓰여져야하는것을 의미한다. 하지만 워커를 어떻게 알수 있을까? 이는 metadata table에 의해서 결정된다. shard를 worker에 맵핑하는 것을 shard placement라고 부른다.
metadata table들을 join해서 답을 얻을수 있다. 이러한 유형의 lookup은 coordinator가 쿼리를 route하기 위해서 하는 것이다. coordinator는 쿼리들을 fragment(github_events_102027과 같은 테이블)에 재작성한다. 그리고 그 fragment들을 적절한 worker에 실행한다.
1
2
3
4
5
6
7
8
9
SELECT
shardid,
node.nodename,
node.nodeport
FROM pg_dist_placement placement
JOIN pg_dist_node node
ON placement.groupid = node.groupid
AND node.noderole = 'primary'::noderole
WHERE shardid = 102027;
1
2
3
4
5
┌─────────┬───────────┬──────────┐
│ shardid │ nodename │ nodeport │
├─────────┼───────────┼──────────┤
│ 102027 │ localhost │ 5433 │
└─────────┴───────────┴──────────┘
github_events 예시에서는 4개의 샤드가 존재한다. 샤드의 수는 테이블마다 설정이 가능하다. Shard count에 대한 내용은 Shard Count를 참고하자.
Citus는 샤드들의 데이터를 보호하기 위해서 replication을 허용한다. 두가지 replicaton mode가 있는데 Citus replication과 streaming replication이 존재한다. 전자는 shard placement에 대한 추가적인 백업을 생성하고 그것들중 어느하나라도 업데이트 되면 쿼리를 실행한다. 후자는 더 효율적이고 PostgreSQL의 streaming replication을 사용하여 전체 데이터베이스를 follower database에 백업한다. 이는 투명하고 Citus metadata table이 필요없다.
Co-Location
shard와 replicas가 원하는대로 노드들에 위치될수 있기때문에 관련된 테이블들의 관련된 행들을 포함하는 샤드들을 같은 노드에 위치시키는 것은 당연한일이다. 이러한 방식으로 join query는 네트워크로 추가적인 정보를 보내는것을 피할수 있고, 단일 Citus node내에서 처리될수 있다.
한가지 예는 store,product,purchase을 가진 데이터베이스이다. 만약 세가지 테이블들이 store_id 칼럼을 포함하고 이 칼럼에 의해서 분산되어있다면, 하나의 store에 제한된 모든 쿼리들은 하나의 worker node에서 효율적으로 실행될수 있다. 더 자세한 설명은 Table Co-Location를 참고하자.
Parallelism
쿼리들을 여러 머신에 분산시키는것은 더많은 쿼리가 실행되도록 허락하고 클러스터에 새로운 머신을 추가하여 processing speed를 증가시킬수 있도록 허락한다. 추가적으로 단일 쿼리를 여러 fragment로 쪼개는것은 processing power를 증가시킬수 있다. 이는 병렬성을 증가시키고, CPU core의 사용을 증가시킨다. 쿼리의 결과는 여전히 coordinator에게 전달되어야하기 때문에 마지막 결과가 compact할때(aggregate function의 경우) 더 명백히 speedup를 볼수있다.
Query Processing은 어떻게 쿼리들이 fragment로 나누어지는지 설명하고 있다.