
프로젝트 배경
기존에 동작하던 앱에서는 1분에 한번씩 Prometheus에 실시간으로 수집되고 있는 메트릭을 쿼리하고 S3에 업로드후 Snowflake 데이터 웨어하우스에 적재를 하는 방식으로 동작하였다.
기존 아키텍처
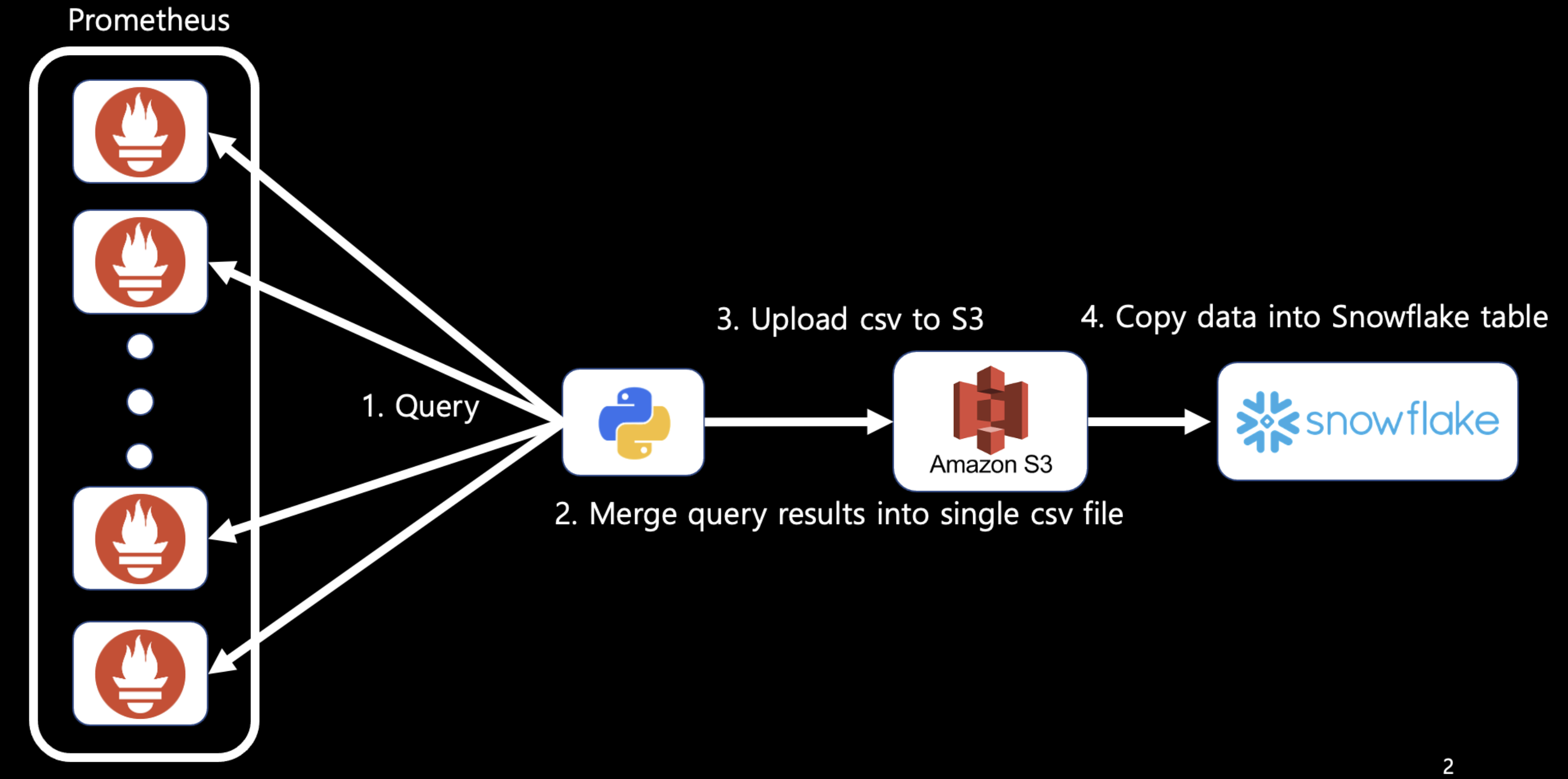
기존 백필 아키텍처

이 방식은 다음과 같은 문제점이 있었다.
- 데이터 backfill의 어려움 : 프로메테우스의 retention은 6시간으로 설정되어있고, retention이 지나면 프로메테우스로부터 데이터를 받아올 수 없다. retention이 지난경우 백필을 원하면 DevOps팀에게 별도의 Prometheus의 cold storage인 Thanos를 요청해야 했다. Prod환경에서 사용중이던 Thanos는 이미 부하가 많이 걸려있는 상황이기 때문에 사용할 수 없다.
- backfill Thanos 부하증가 : 몇가지 메트릭의 경우 Thanos에서 대량의 데이터를 로드하여 메모리에 불러오다보니, 자주 장애가 나는 현상이 있었다. Thanos는 리소스를 많이 필요하므로, DevOps팀에서 backfill Thanos 배포를 달가워하지는 않았다.
- backfill의 불편함 : 언제부터 백필해야 되는지 사람이 수동으로 판단해야 하며, 수동으로 백필 애플리케이션을 재 배포해야 한다. 예를들어, 특정 틱에 쿼리는 성공적으로 수행되었지만 S3에 적재가 안되었거나 Snowflake에 적재가 안된경우 backfill 애플리케이션을 수동으로 배포해주어야한다.
- 데이터 유실이 발생하기 쉬운 구조 : query,S3 upload, snowflake 적재과정에서 어느 한 step에서 잘못되면 데이터가 유실된다.
위 문제를 해결하기 위해 이 프로젝트를 수행하게 되었다.
Data pipeline의 요구사항
해당 데이터 파이프라인은 다음과 같은 요구사항이 있다.
- 실시간으로 데이터가 적재될것
- 데이터 유실이 없을것
구조 개편과정
1. 데이터 유실방지 방법에 대한 고민
S3 적재, Snowflake 적재 도중 데이터 유실을 방지 하기위해서 Kafka consumer의 offset commit 기능을 떠올렸다. Kafka를 사용하게 되면서 중복로그가 쌓일수 있기 때문에 중복을 어떻게 제거할까도 고민했다. Snowflake는 Unique 키를 지원하지 않기 때문에, 중복 row가 생길수 있었고 이를 위해서 data를 적재하기 전에 해당 row를 delete후 insert하는 방식을 선택했다(merge into 쿼리를 사용하는것도 고려했지만 테이블 풀 스캔이 발생할것 같아서 효율적이지 않을것이라 생각했다). 그래서 나온것이 V1 아키텍쳐이다.
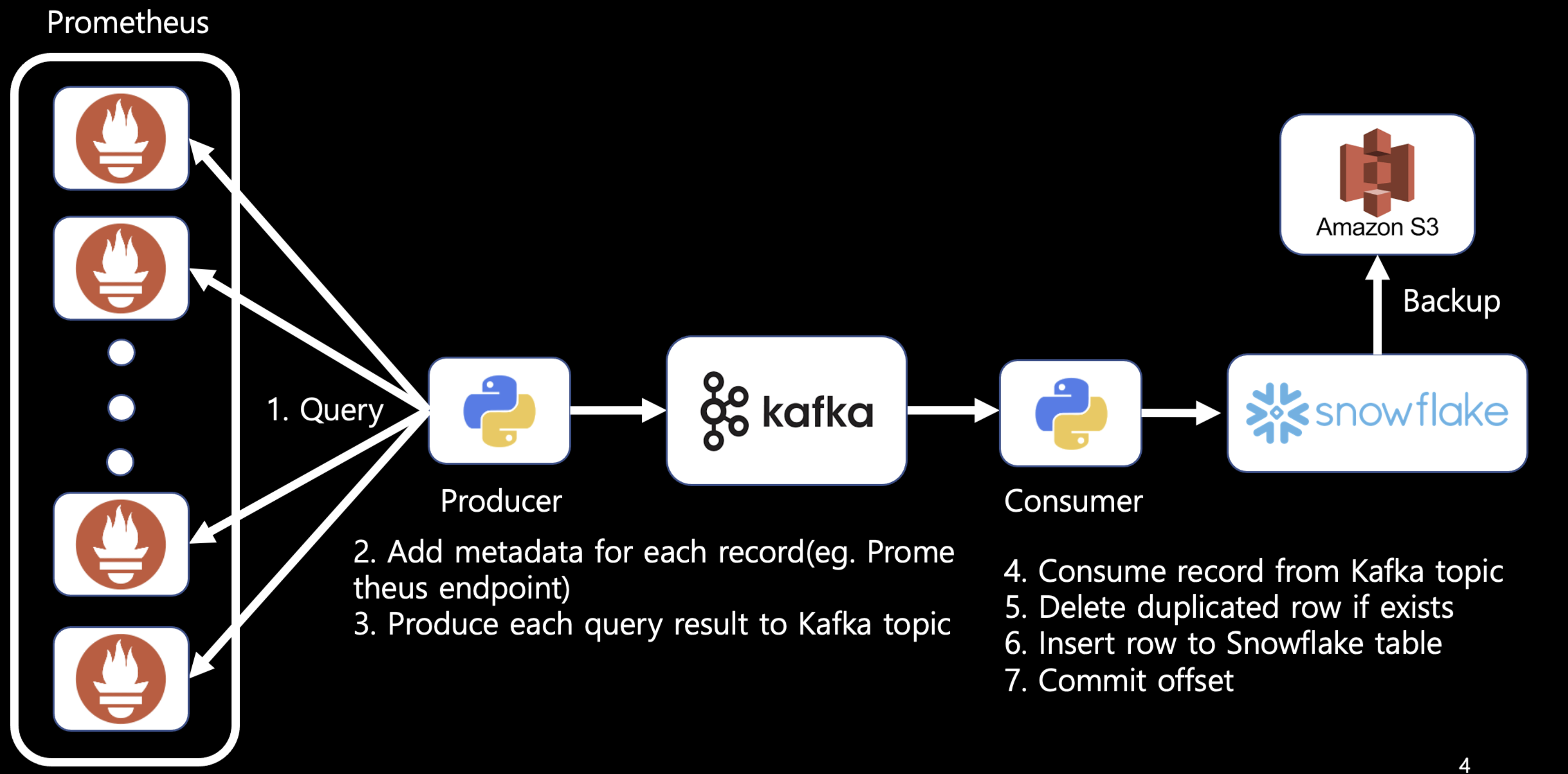
Kafka consumer app에서 snowflake에 delete,insert 쿼리를 하나의 트랜잭션으로 처리하기 위해서 다음 처럼 구현했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
## Kafka-python
def run(self):
self.logger.info("Started running")
try:
while not self.stop_event.is_set():
msg_pack = self.consumer.poll(timeout_ms=settings.POLL_SECONDS)
self.logger.info(f'number_of_message : {len(msg_pack)}')
for tp, msgs in msg_pack.items():
for msg in msgs:
decoded_key = msg.key.decode('utf-8')
decoded_value = msg.value.decode('utf-8')
self.logger.info(
f"{tp.topic}:{tp.partition}:{msg.offset}: key={decoded_key} value={decoded_value}")
self.delete_and_insert_row(decoded_value)
except Exception as e:
self.logger.error(e)
slackManager.send_slack_message(e)
finally:
self.consumer.close()
self.logger.info('Consumer closed')
def delete_and_insert_row(self, msg: str):
msg_dict = json.loads(msg)
values_str = self.convert_to_value_str(msg_dict)
delete_query = f"DELETE FROM {self.table_name} WHERE TIMESTAMP='{msg_dict['timestamp']}' AND CLUSTER='{msg_dict['cluster']}';"
# print(delete_query)
insert_query = f"INSERT INTO {self.table_name} VALUES {values_str};"
# print(insert_query)
combined_query = f"{delete_query} {insert_query}"
try:
with connector.connect(
account=settings.SNOWFLAKE_ACCOUNT,
user=settings.SNOWFLAKE_USER,
password=settings.SNOWFLAKE_PASSWORD,
database=settings.DATABASE,
schema=settings.SCHEMA
) as conn:
conn.autocommit(mode=False)
cursor_list = conn.execute_string(combined_query)
for cursor in cursor_list:
query_id = cursor.sfqid
while conn.is_still_running(conn.get_query_status(query_id)):
time.sleep(0.1)
conn.commit()
self.logger.info(f"DML commited : {combined_query}")
except Exception as e:
print(e)
self.logger.error(e)
slackManager.send_slack_message(e)
return False
return True
def convert_to_value_str(self, msg_dict):
value_list = [f"'{str(val)}'" for val in list(msg_dict.values())]
return f'({",".join(value_list)})'
하지만 로그하나당 실행시간이 5초정도 소요되어 실시간으로 테이블을 업데이트할수 없었다.
Snowflake에서 빠르게 적재하기 위해서 결국 S3 Stage에 적재후 Snowflake에 적재하는 방식으로 돌아가기로 했다. 다만 이 경우에는 중복을 보장할수 없었다. 결국 BI에서 Snowflake에 쿼리시 중복을 제거할수 있도록 해야했고, 원본 테이블에서 DISTINCT 옵션으로 중복을 제거할수 있으리라고 기대했다. 하지만 Prometheus로 부터 받아온 데이터는 다음과 같은 특징이 있었다.
- 우리가 쿼리하는 cluster는 여러 shard로 구성되어있고, 각각의 Shard에는 Prometheus가 HA를 위해서 2대로 실행되고 있었다. 이때 각각이 scrape하는 시점이 달라서 같은 시각에 대한 데이터라도 다른 결과가 적재되어 있었다. 즉, 아래와 같이 특정 cluster shard에 쿼리를 했을때 다음과 같이 2개의 값중 랜덤하게 리턴하게 된다.
- 그림
그러므로 우리가 중복로그를 필터링 하려면 쿼리에서 value값을 제외한 모든 필드들에 대해서 같은지 확인해야 한다. 그리고 그중에는 timestamp,cluster,shard정보가 항상 존재해야만 어느 cluster shard로 부터 무슨 시간에 대한 데이터인지 구별할 수 있다.
그래서 해당 필드들을 producer앱에서 메시지를 produce하기전에 추가해주어야 했다.
1
2
3
4
5
# All message should have cluster info to be identified uniquely
if 'cluster' not in metric_dict:
metric_dict['cluster'] = get_cluster_from_url(url)
if 'prom_shard' not in metric_dict:
metric_dict['prom_shard'] = get_shard_from_url(url)
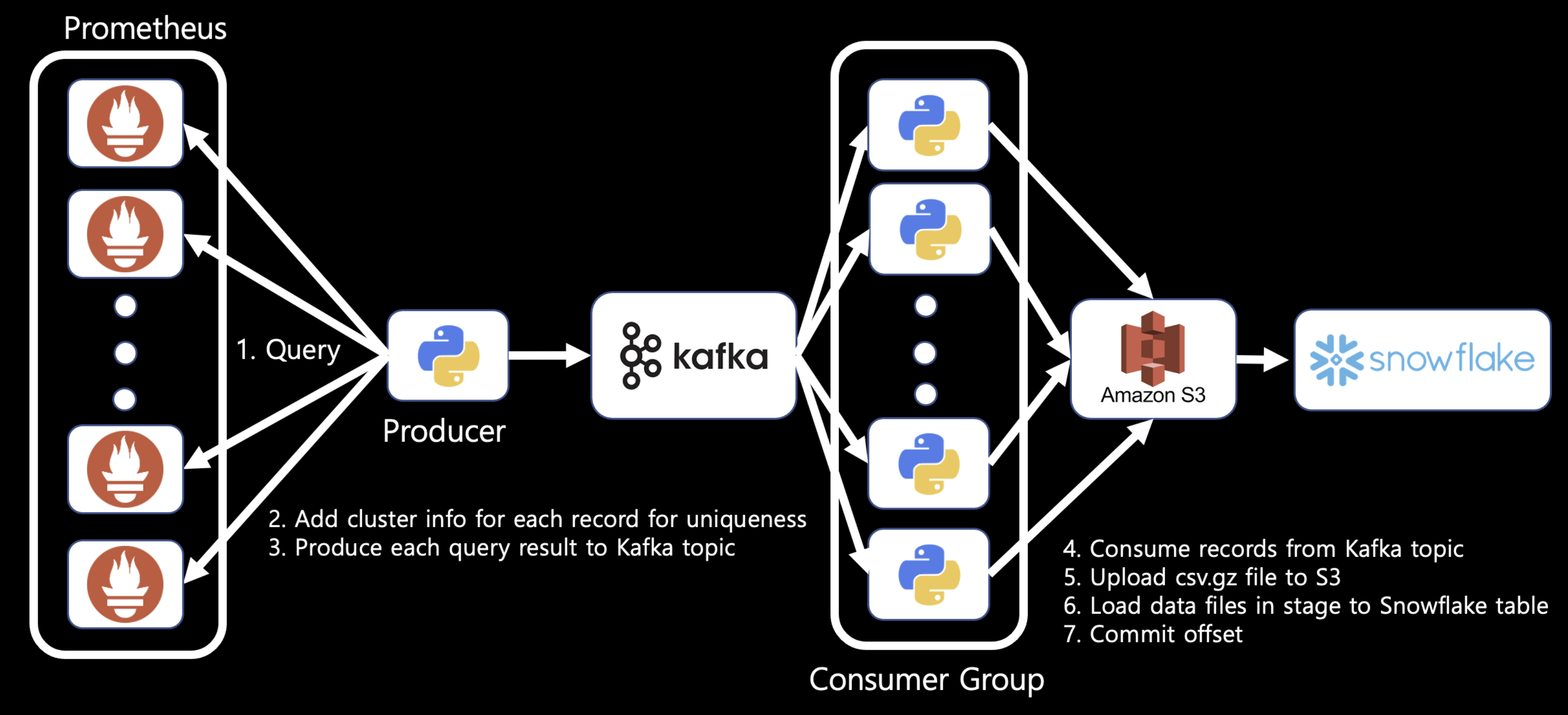
2. Consumer lag에 따라 유동적으로 consumer수 조정하기
그 다음으로 고려해야 할것은 Consumer의 병렬성이었다. 유저의수가 몰리는 시간대의 경우 메시지의 수가 증가하게 되고, consumer lag에 맞게 consumer의 수를 유기적으로 조정하는것이 필요했다. 그렇게 해서 나온 구조가 v2 아키텍쳐이다.
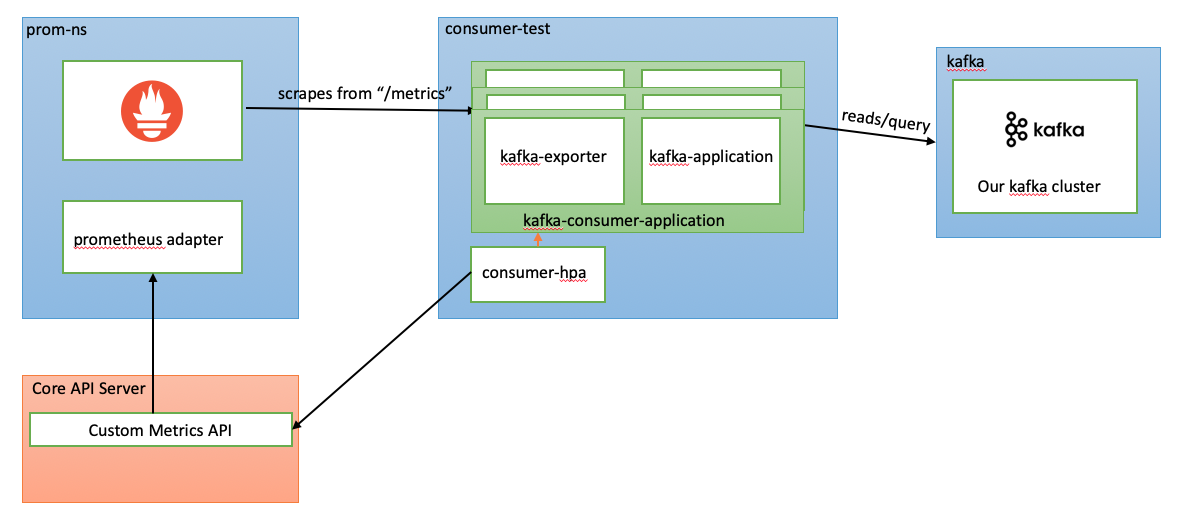
현재 컨슈머앱들은 하나의 Kubernetes Pod로 실행되고 있었고, HPA를 적용하기 위해서 Horizontal Pod Autoscaling (HPA) triggered by Kafka event 글을 참고했다. 이 글이 제시한 방법은 아래와 같이 consumer pod에 kafka exporter를 띄워서 msk broker에 있는 메트릭들을 수집하고 prometheus adapter에서 custom metric api server를 생성하여 HPA에게 kafka consumer lag정보를 제공해주는 방법이다.
위 글이 제시한 방법데로 Prometheus Adapter Chart의 value를 구성하면 메트릭을 정상적으로 받아오지 못해서, 아래와 같이 values.yaml을 구성했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
prometheus-adapter:
prometheus:
port: 9090
url: http://kube-prometheus-prometheus
rules:
custom:
- seriesQuery: '{__name__="kafka_consumergroup_lag",namespace!="",service!="",pod!="",topic!="",consumergroup="MetricConsumerGroup"}'
resources:
template: <<.Resource>>
name:
matches: ^kafka_consumergroup_lag$
as: kafka_consumergroup_lag
metricsQuery: 'avg_over_time(kafka_consumergroup_lag{<<.LabelMatchers>>}[2m])'
위 방법은 pod autoscaling시 kafka exporter 컨테이너 또한 복제가 되므로, 비효율적이다. kafka exporter 컨테이너는 한개이상이 필요없다. Kafka exporter 컨테이너를 consumer pod에서 분리하기 위해서, 외부에 kafka exporter를 단독으로 포함하는 deployment를 생성하고 prometheus adapter에서는 external metric api 서버를 생성하여 해결하려고 했다. 하지만 현재 k8s cluster에는 이미 external metric api server가 존재하였고 추가적으로 생성하는것이 불가능했다. 이미 존재하는 external metric api server은 keda metric adapter에 의해서 생성되고 있었고, 결과적으로 keda를 사용하여 topic별 consumer lag값으로 autoscaling 할수 있었다.
3. 메트릭 프로듀서앱의 장애상황에 대한 대처
하지만 현재구조에서는 매분마다 데이터 수집로직이 도는데, Producer Pod이 실행도중 종료가 되면, 데이터가 유실이 발생할 수 있다. Producer Pod이 중도에 fail되더라도, Producer가 수행하고 있던 job정보를 저장해둘 독립적인 저장소가 필요했다. 여기서 처음으로 생각했던 해결책은 Producer app에서 1분마다 job을 스케줄링 하기위해서 사용했던 APScheduler 모듈의 backend를 redis로 사용하여 job정보를 외부 저장소에 저장하는 방법을 생각했다. 하지만 테스트를 다음 처럼 해보니 아주 큰 문제점이 있었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
import logging
import os
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime, timedelta
from apscheduler.jobstores.redis import RedisJobStore
from apscheduler.executors.pool import ThreadPoolExecutor
jobstores = {
'default': RedisJobStore(jobs_key='test_job_key', run_times_key='test_run_time_key', host='localhost', port=6379, password='1234')
}
executors = {
'default': ThreadPoolExecutor(1),
}
job_defaults = {
'coalesce': False,
'max_instances': 3,
'misfire_grace_time': 100000
}
scheduler = BlockingScheduler(timezone='Asia/Seoul',jobstores=jobstores, executors=executors, job_defaults=job_defaults)
def alarm(args):
print('in alarm')
scheduler.print_jobs('default')
#print('Alarm! This alarm was scheduled at %s.' % time)
print(f'args : {args}')
#sys.exit()
#raise Exception("ERROR!")
def my_listener(event):
print(event)
print('in listener')
#scheduler.print_jobs()
if event.exception:
print('The job crashed :(')
else:
print('The job worked :)')
def metric_batch():
for i in range(3):
alarm_time = datetime.now() + timedelta(seconds=i+1)
scheduler.add_job(alarm, 'date', run_date=alarm_time, args=[f'hello world {i}'])
scheduler.print_jobs('default')
scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
print('To clear the alarms, run this example with the --clear argument.')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
pass
if __name__ == '__main__':
metric_batch()
하지만 job이 정상적으로 실행후 job정보가 redis에서 삭제가 되어야하는데, job이 실행하는 시작시점에 job정보가 사라지는 문제점이 있었다. 물론 job의 결과에 따라서 job을 다시 스케줄링하는 방법이 있었지만 실행도중 fail이 되는경우 해당 job을 다시 스케줄링할수 있는 방법은 없었다. 따라서 Producer Pod가 실행도중 종료되더라도, 실패한 job부터 실행할 수 있도록 Redis와 JobGenerator라는 앱을 추가한 버전이 v3 아키텍쳐이다.
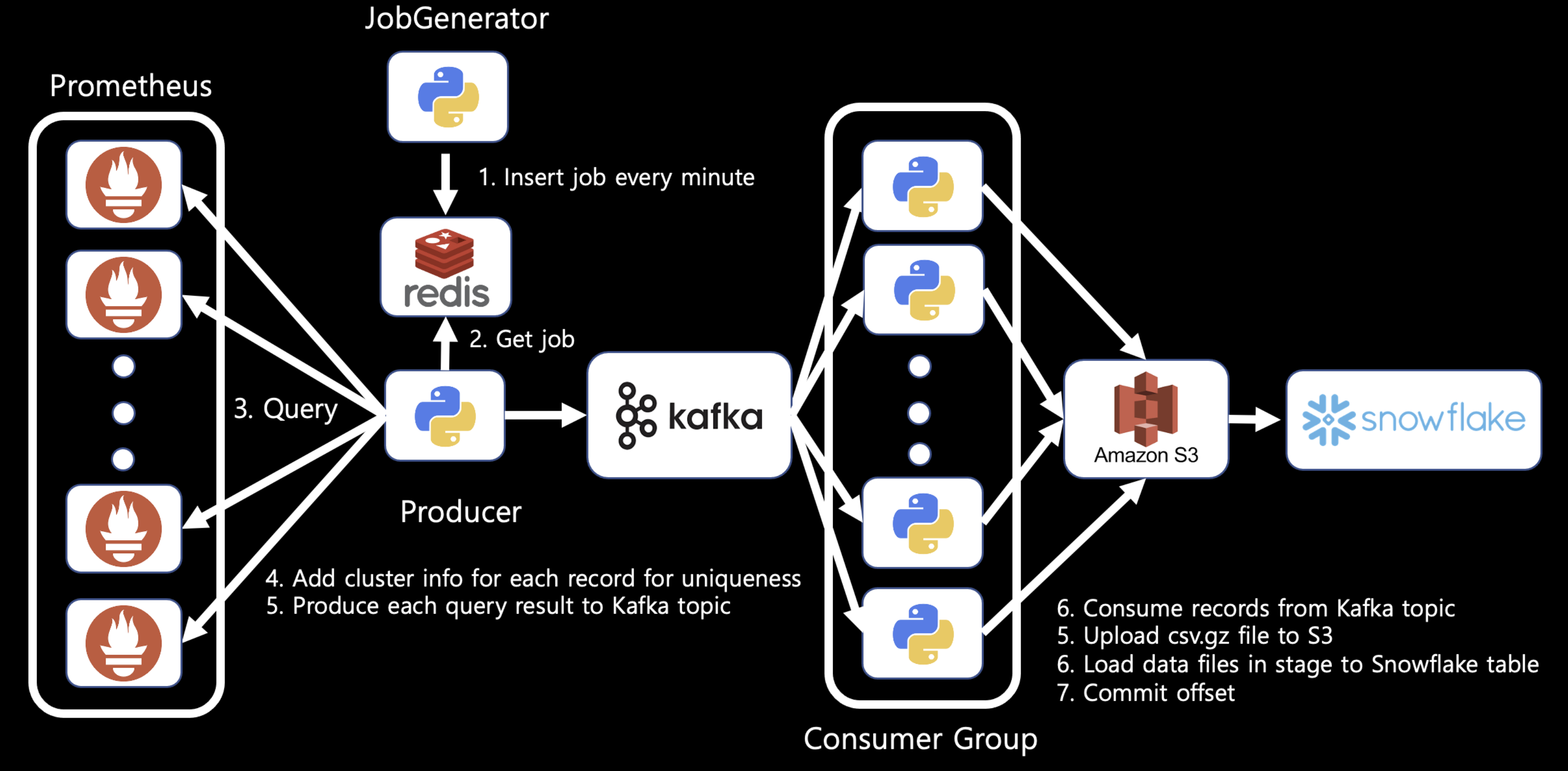
위 구조에서는 JobGenerator앱은 deployment 리소스를 사용해서 replica수를 3으로 설정하여 배포하였다. 따라서 3개의 Pod중 어느 2개의 Pod가 fail이 되더라도 job 정보를 계속 갱신할 수 있도록 하였다.
4. 적재대상이 되는 테이블의 칼럼 리스트 로드 자동화
원래 구조에서는 적재 대상이 되는 테이블의 칼럼 리스트를 python 리스트에 하드코딩 하는 형태로 구현되어있었다. 따라서 추가적으로 2022년 2월 기준으로 새로운 메트릭 수집 요청시 코드를 수정하고 도커 빌드를 새로해서 이미지 태그를 업데이트를 해야해서 번거롭다는 문제점이 있었다. 따라서 컨슈머 앱의 초기화 과정에서 적재해야할 테이블을 대상으로 칼럼 리스트를 로드할 수 있도록 자동화를 진행했다.
1
2
3
4
5
6
7
8
9
def get_table_list(database: str, schema: str):
query = f'SHOW TABLES IN {database}.{schema};'
table_list = []
with get_snowflake_conn() as conn:
cur = conn.cursor()
cur.execute(query)
for row in cur:
table_list.append(row[1].lower())
return table_list
이로서 새로운 메트릭 요청이 들어오면 헬름차트에 대상 쿼리가 되는 promQL과 대상 테이블 정보만 추가하고, Snowflake에 대상 테이블만 생성해주면 되어서 유지보수성이 향상되었다.
개편구조의 장점
- 안정적인 데이터 처리 : 메트릭별 JobGenerator가 replica 3으로 운용중이고, Producer,Consumer는 stateless하므로 중도에 fail이 되더라도 안전하게 데이터를 다시 처리 가능함. offset commit을 통해서, 카프카에서 데이터를 컨슘하여 snowflake에 적재하는 과정에서 at least once를 보장할 수 있다.
- DevOps팀에게 backfill용 타노스를 요청할 경우가 거의 없어진다.
- 빠른 데이터 처리 : 대부분의 부하는 s3 upload 및 snowflake load에서 발생하는데 여러 컨슈머에서 병렬적으로 로그를 처리할 수 있으므로 속도가 빠르다
개편구조의 한계점과 해결책
결국 데이터 유실을 방지하기 위해서, Kafka를 도입하였고 Snowflake에 Unique 키를 지원하지 않음으로 인해 중복로그가 Snowflake에 적재될수 있게 되었다. 실시간으로 갱신되어야 하는 데이터가 아니라면 중복 row제거를 하는 batch를 돌릴수도 있겠지만, 실시간으로 갱신되어야하는 대시보드에서는 쿼리시점에 중복로그를 필터링 해야했다.
즉 다음 쿼리처럼 필터링을 해야했다.
1
2
3
4
5
SELECT *
FROM
(SELECT *, ROW_NUMBER() OVER(PARTITION BY TIMESTAMP,PROM_SHARD,CLUSTER ORDER BY _COUNT) AS rn
FROM DEV.SERVER.INGAME_AGGREGATED_CCU)
WHERE RN=1;
다만 저렇게 했을때, 테이블 풀스캔을 한다는 문제점이 있어서 쿼리시간이 지나치게 오래걸리는 문제점이 있었다. 이를 해결하기 위해서 FROM절에 필요한 하루치 데이터만 가져와서 중복로그를 제거하는 방식으로 수정되었다.
참고
v3 아키텍쳐를 생각하는 시점에 아래와 같은 방법이 떠올랐다.
- snowflake에 적재되었는지 검사
- 적재 안되었으면 query, s3 upload, snowflake load
- 이중 실패했으면 1번 부터 다시 시작
- 만약 성공했으면 해당 job 삭제
위 방법의 가장 큰 장점은 중복 적재가 안되는 것이고, 현재 중복로그 판별을 위한 칼럼을 추가할 필요없이 현재 테이블 구조대로 사용이 가능하다는 것이 장점이다.
하지만 로그가 많이 들어오는 경우, v3구조처럼 데이터를 병렬적으로 처리할 수 없다. 결국 데이터 중복을 제거하기 위해서 실시간성을 포기해야하는 것이다.